Building a Robust Machine Learning Operations Infrastructure
Creating a reliable and flexible MLOps infrastructure is critical for organizations leveraging machine learning in production. In this post, I’ll explore practical challenges that emerge when deploying ML systems and propose pragmatic solutions using open-source tools and standard workflows.

The Challenge of Production ML Systems
After deploying a machine learning model in production, a new set of challenges emerges. The model pipeline typically involves data storage (like S3), orchestration tools (such as Airflow, Prefect, or Flyte), and back to storage for processed results. But this simple flow becomes complex when we consider the full ML lifecycle.
Let’s address the common incremental issues that arise and propose practical solutions:
Testing Models in Production
Challenge: How do you verify a newly deployed model performs well on critical test data? Pragmatic Solution: Create a dedicated testing workflow that:
- Automatically runs inference on a curated set of critical test cases
- Compares performance against predefined thresholds for precision, recall, etc.
- Generates detailed reports highlighting any concerning areas
| |
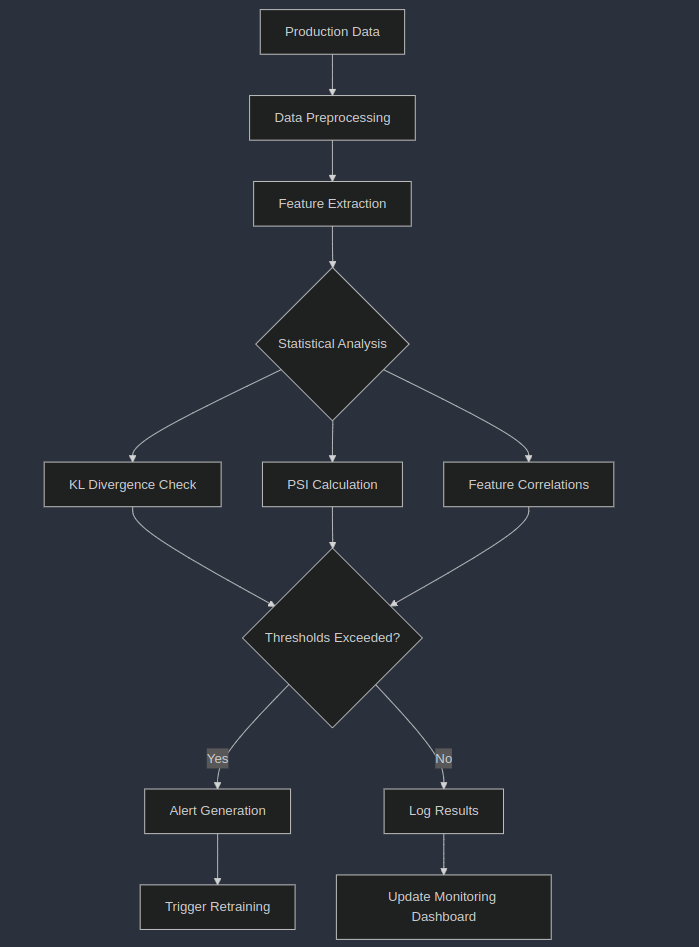
Detecting Model Drift
Challenge: Models degrade over time as data distributions change. How do you proactively detect this? Pragmatic Solution: Implement an automated drift detection workflow that:
- Periodically samples production data
- Calculates key statistical measures like PSI (Population Stability Index) or KL divergence
- Compares feature distributions between training data and current data
- Triggers alerts when significant drift is detected
Model Rollback Strategy
Challenge: What if a deployed model starts performing poorly or causing issues? Pragmatic Solution: Implement a robust model registry integrated with your serving infrastructure:
- Version and tag all models in the registry
- Maintain metadata about each model version (training data, performance metrics)
- Create fast-path rollback workflows that can quickly revert to prior stable versions
- Automate the rollback process when critical metrics drop below thresholds
Flexible Model Serving
Challenge: How do you create a model serving infrastructure that handles updates, scaling, and canary deployments? Pragmatic Solution: Build a model serving layer that:
- Integrates directly with your model registry
- Supports A/B testing and canary deployments
- Includes automatic scaling based on traffic
- Enables request/response logging for performance monitoring
- Implements circuit breakers to prevent cascading failures
Changing Model Architecture
Challenge: What if you need to fundamentally change your model architecture? Pragmatic Solution:
- Create modular workflow definitions that can accommodate different model architectures
- Use environment management tools like Docker and conda to handle different dependencies
- Implement feature stores for consistent feature engineering across - model versions
- Design input/output interfaces that remain stable even as architectures change
Model Comparison
Challenge: How do you effectively compare multiple model candidates? Pragmatic Solution:
Create a dedicated model comparison workflow that:
- Runs several models on the same evaluation dataset
- Computes performance metrics for each model
- Generates visualizations to compare metrics
- Automatically selects the best model based on predefined criteria
Keep the model registry at the center of this process to maintain versioning
Here are the few more best practices:
Start with a Minimal Viable Pipeline: Begin with the essential components and iterate
Adopt Standard Tools: Leverage battle-tested open-source tools:
- MLflow for experiment tracking and model registry
- Kubeflow or Flyte for workflow orchestration
- Seldon Core or KServe or custom gRPC / FastAPI for model serving
- Feast for feature stores
- Evidentialy for drift detection
- Prometheus and Grafana for monitoring
Centralize Configuration: Use a central configuration repository for all workflow parameters
Build for Failure: Assume components will fail and design graceful degradation
Standardize Metrics: Define organization-wide standards for model evaluation
DataBricks : ALternative Solution
Databricks provides a unified analytics platform that can significantly enhance and streamline any MLOps workflows. With the overhelming open source tools. Databricks is the safe approach for the MLOps ecosystem.

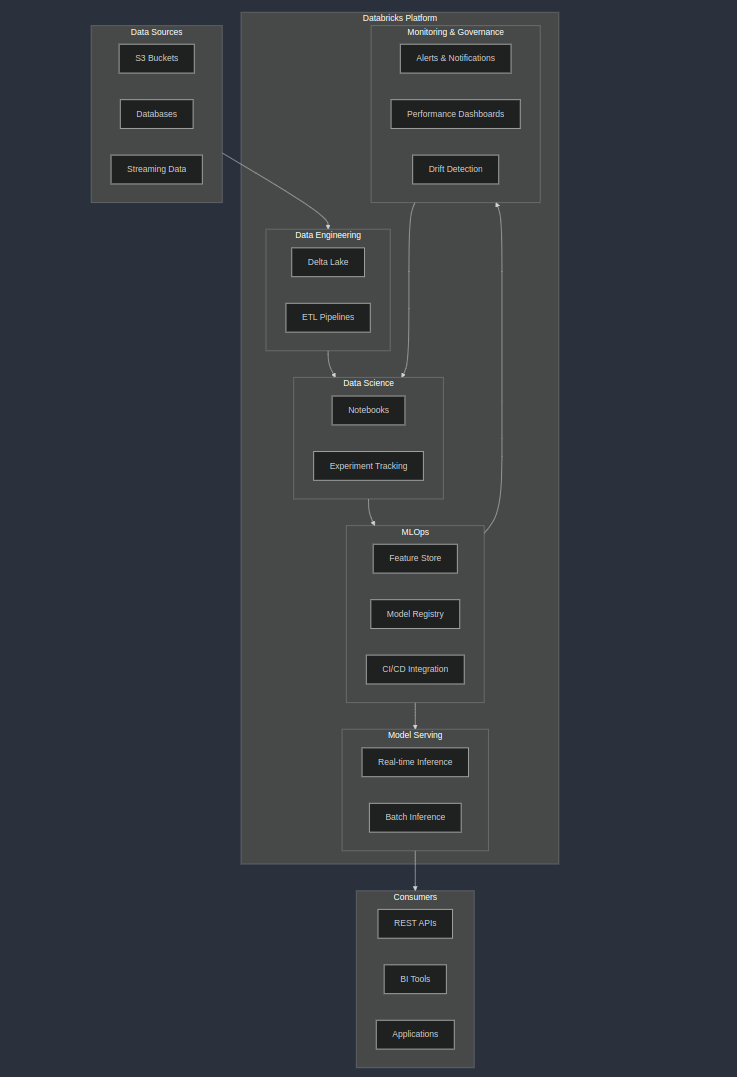
Databricks claims faster ML development cycles and learn more about it at its academy : https://customer-academy.databricks.com/
