Background
In this case study, Artificial Intelligence based system is used to take buisness decisions. The study is based on a e-commerce company which ingest lots of data like images, quarterly reports, invoices, customer feedbacks, customer reviews with images, etc. It would be great if this large amount of data is automatically categorized or grouped together. Previously, a machine learning team in the company had created a model to classify the input data. But the nature of the e-commerce data, new product launches, new customer feedbacks, etc. are not predictable. Thus, the model needs to be retrained frequently. The company is looking for a solution that can automatically perform and help the analyst to get the insight from the unstructured data.
Image Clustering
Lets dive in the Technical side of the case study. There are multiple paradigms of supervised machine learning, such as classification, object detection, and segmentation, among others. There are many robust supervised algorithms; however, to achieve high accuracy, we need labeled data, which is costly and time-consuming. Clustering is an unsupervised learning technique that can be applied to unlabeled datasets. It is one of the most interesting and challenging problems in the field of computer vision. The goal of image clustering is to group similar images together in the same cluster. There are also other forms of machine learning, such as semi-supervised learning, reinforcement learning, and transfer learning, which are not covered in this article. The main goal of the article is to explore the image clustering technique beyond its traditional use cases.
Image clustering: View from Professional settings
In real world scenario, a company could ingest images from multiple sources. The image sizes / format , interest point in the image are unknown. To fetch the insight from the unstructure settings is really hard and requires alot of regular hand picked tuning. Thus, Many companies moves towards supervised learning where they sample the data and label them and train a supervised model to get the insight.
However, the unsupervised learning is also a good choice when the data is unpredictable and the labels are not available. The image clustering is one of the unsupervised learning technique which can be used to cluster the images based on the similarity and thus using this in the automated workflow to get the insight from the unstructured data.
Methodology
Image clustering systems can be divided into two main categories:
- Image feature Generation Image pixels are stored as matrics in the computer. The size of image matrics varies based on the image size and format. Thus Image pixel couldnot be used directly to custering algorithm due to its size and variability. Image features can be generated using various methods like neural networks, computer vision algorithms like SIFT, SURF, ORB, etc. Sometimes feature reduction techniques like PCA, LDA, etc are used to reduce the dimensionality of the features.
- Feature clustering After a feature is generated, the clustering algorithm is applied to the features to cluster the images. The clustering algorithm can be K-means, DBSCAN, Hierarchical clustering, etc.
for the sake of this study, we are using a small dataset of brand logos. However in the study properitery e-commerce data [ logos from pdfs/ document ] are used. 
Note: It really depends on the company data, sometimes the whole image are used to generate the features and sometimes the interest points are used to generate the features. Segment Anything model can be used to generate the interest points. Here, an invoice is parsed by the model when the text prompt is logo and the bounding box over the Tesla logo is generated.

Model Web Demo: Segment Anything
Image Feature Generation
The latest trend of Attention based models outperforms the traditional computer vision algorithms. The attention based models like ViT, ResNet, EfficientNet, etc are used to generate the features. Likewise, there are multi model models like CLIP, DALL-E, etc which are used to generate the features. Using the multi model models, the features can be used to compared with the possible text data and thus can be used to generate the insight from the images.
for the example of the image clustering, we will be using the openAI’s CLIP model to generate the features.
| |
a good alternative to the CLIP model is the VIT model.
| |
Resource to browse the models for feature generation: Huggingface
Once the model is loaded, we can generate the features using the model.
| |
It is important that the processor should be feed in the batch image data. since the the underlying model is trained on the batch image data. Thus batch image helps to achieve better throughput for generating the features.
Image clustering Algorithm
Once the features are generated, the clustering algorithm is applied to the features. The clustering algorithm can be K-means, DBSCAN, Hierarchical clustering, etc. Here, we choose Faiss for the clustering as it has both CPU and GPU support.
| |
Lets see How it creates the cluster. 
The image clustering result doesnot make sense. lets update the hyperparamter and create the clustering again with different number of clusters.
| |
The clustering result is much better. 
The cluster result is better than the previous as we increased the number of clusters. The number of clusters can be determined based on the domain knowledge of the dataset or using the metrics.
Image clustering Metrics
Finding the best cluster size is a challengine task. The perfect cluster size can be predicted if some domain knowledge of the dataset is available. In the absence of domain knowledge, we can use the metrics to find the best cluster size.
Image clustering can be compared based on two types of metrics.
- Extrinsic metrics:
Extrinsic metrics are based on the ground truth labels. Some of the popular extrinsic metrics are:
- Adjusted Rand Index (ARI)
- Normalized Mutual Information (NMI)
- Fowlkes-Mallows Index (FMI)
- Homogeneity, Completeness, and V-measure
- Precision, Recall, and F1-score
- Confusion matrix
However, we are into the unsupervised learning, we will not be using these metrics.
- Intrinsic metrics:
Intrinsic metrics are based on the clustering results. Some of the popular intrinsic metrics are:
- Silhouette score
- Davies-Bouldin Index
- Calinski-Harabasz Index
- Gap statistic
- Elbow method
Lets see how we can use these metrics to evaluate the clustering results.
elbow method is used to find the best cluster size.
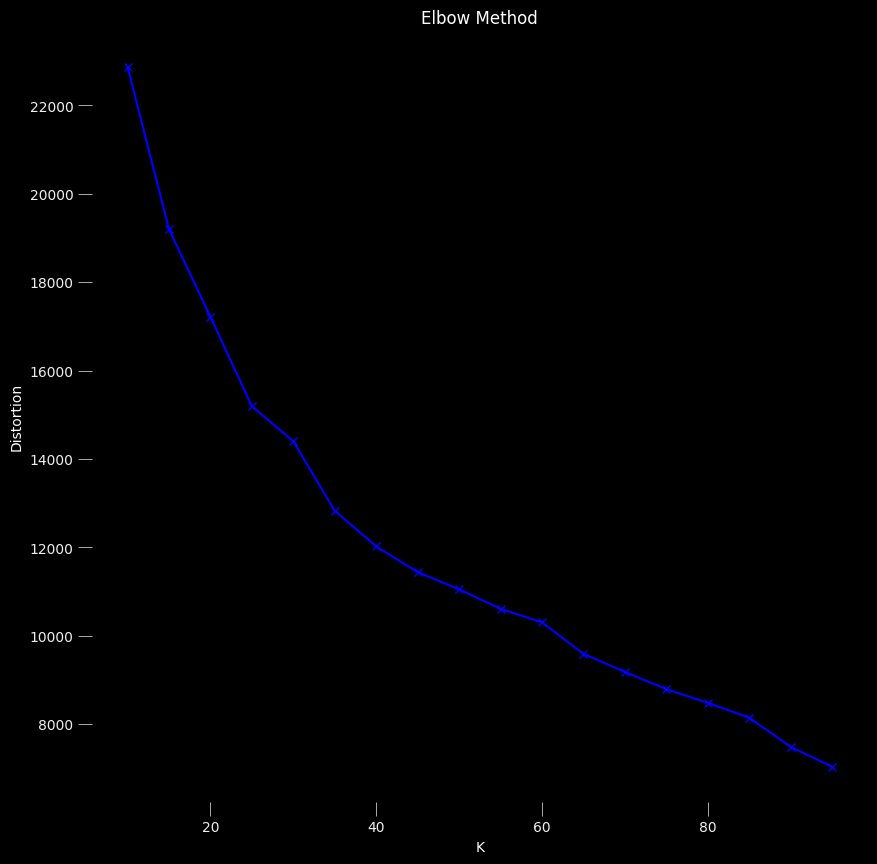
The elbow method is used to find the best cluster size. The best cluster size is the point where the curve starts to flatten. In the above image, the best cluster size is 35/40.
Similarly, other metrics can be used to evaluate the clustering results.
The blog only highlights the specfic part of the image clustering system. All the necessary code snippets are provided to get started with the image clustering. Many software enhancement and glue code are skipped for the sake of the article.
Result
A image clustering system is created and implemented in the system and the data is forwarded to the analyst for the further analysis. The system is able to cluster the data based on the cluster and thus necessary action can be taken much faster. As the system is automated, many documents gets labelled eventually and thus labelling the cluster is much easier than labelling the whole dataset.